ES 架构
Segment
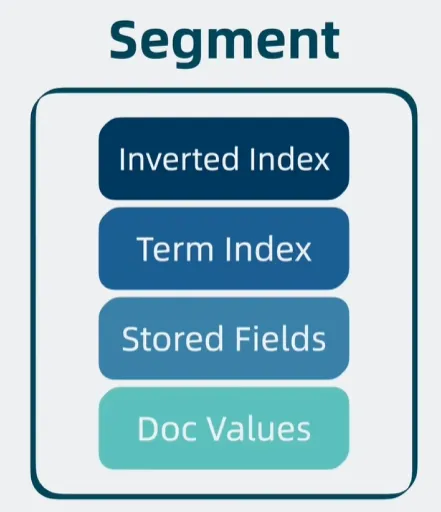 Segment 是具备完整搜索功能的最小单元
Segment 是具备完整搜索功能的最小单元
- 倒排索引(Inverted Index,用于搜索文档)
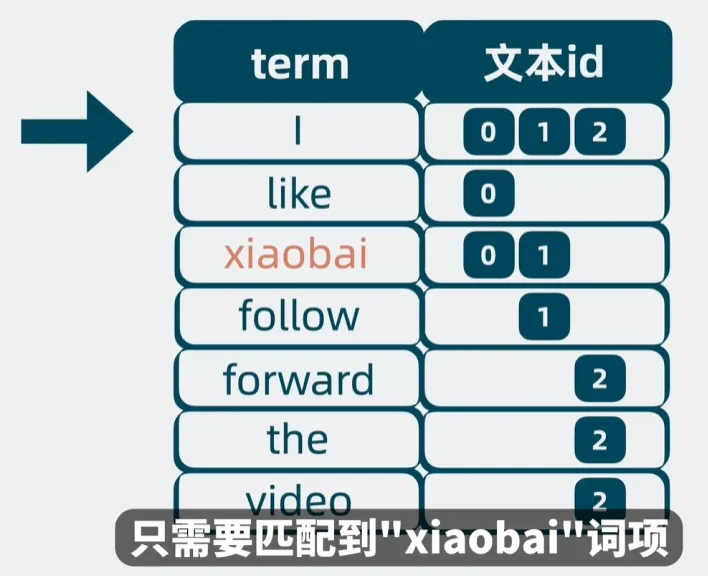
- 分词得到词项(term),词项对应包含该词的文档 id 列表
- 将词项按字典序排序,构建词项字典(term dictionary),可以通过二分来查询需要的词项
- 倒排索引 = 词项-文档 id 列表对 + 词项字典
- 倒排索引结构图
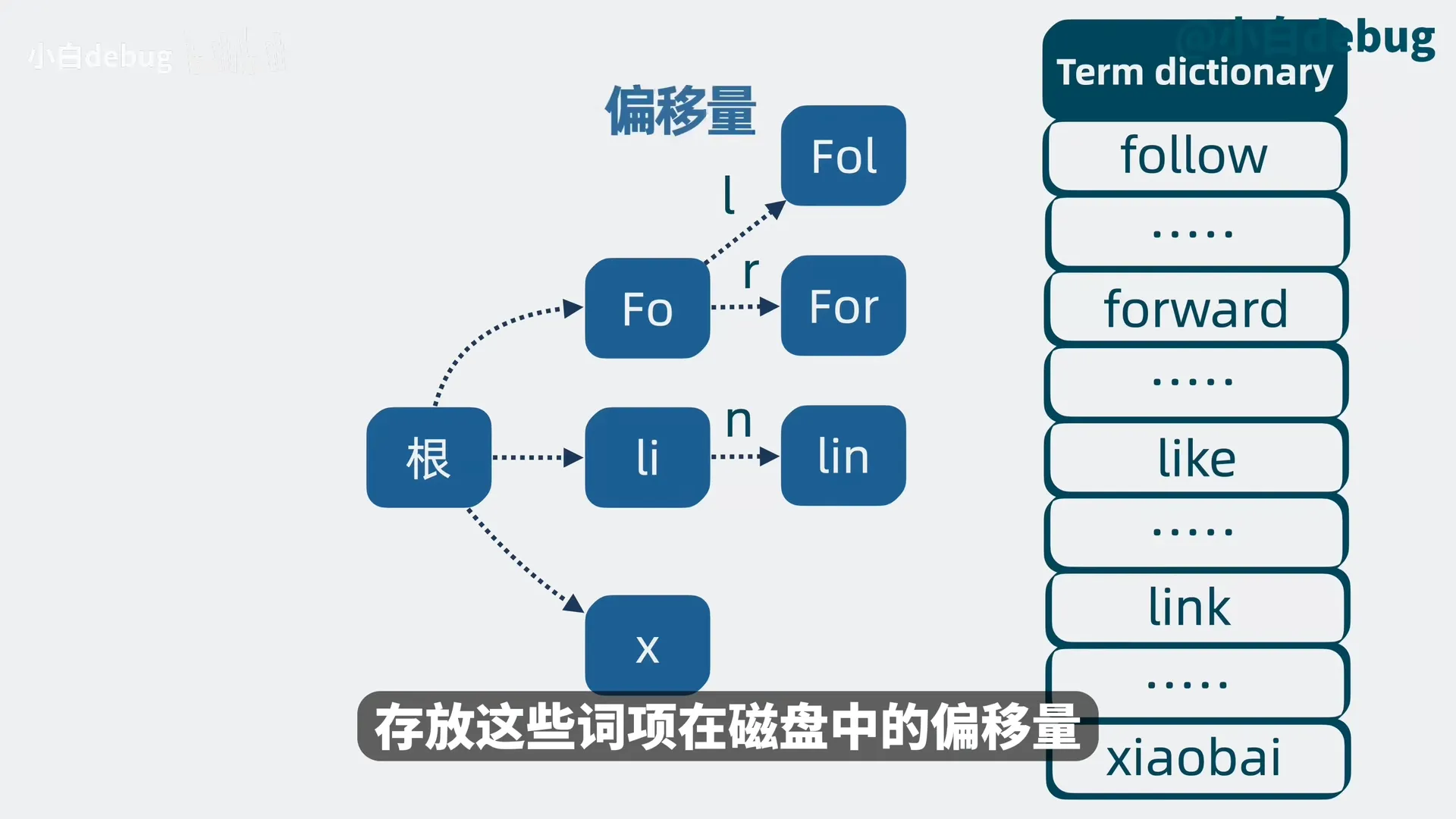
- 词项索引(Term Index,用于加速搜索)
- 词项按前缀构建前缀树,叶子节点存储词项在磁盘中的偏移量,相较于整个倒排索引更适合放入内存
- 词项索引结构图
- Stored Fields(存放文档信息)
- 行式存储结构,每行存储一个 id 和对应文档全文
- 根据词项索引获取词项,得到对应的文档 id 后就可以到 Stored Fields 中获取文档全文了
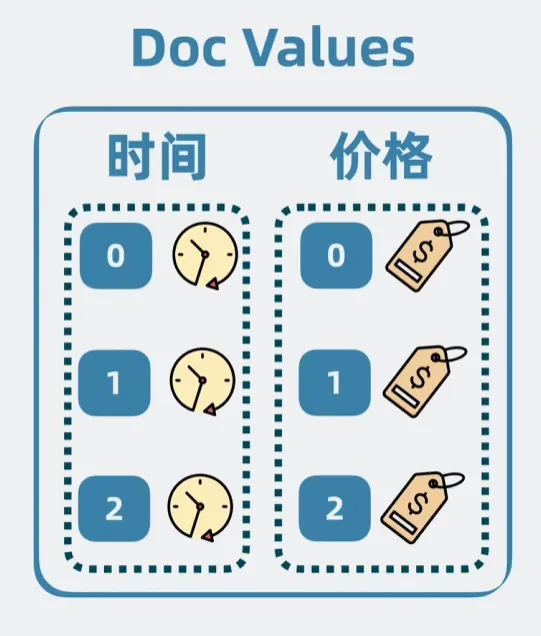
- Doc Values(排序和聚合)
- 空间换时间:将各个文档的指定字段集中存放,需要排序时将该字段一次性读取出来
- Doc Values 结构图
Lucene
ES 是基于开源基础搜索库 Lucene 构建的
- 对于单个 segment,如果要新增文档,要更新整个 segment 的所有信息,并发写性能差,所以设定 segment 一旦生成就无法修改,要新增文档就新建一个 segment
- 旧 segment 只负责读,写则生成新 segment
- 不定期合并若干小 segment
- 不定期合并的多个 segment 就是 Lucene
ES 对 Lucene 的优化
将 Lucene 扩展到多个,由此考虑高性能、高扩展、高可用的问题
高性能
- 考虑数据冗杂,高并发查询会争抢 Lucene 计算资源:对数据进行分类,每个类别有一个 index name,不同类别写入不同 Lucene,对于不同类别的查询就会分散到各个 Lucene 中,降低单个 Lucene 的读写压力
- 考虑分散单类别的读写压力:将单个 index name 下的同类数据拆分为多个分片(shard),每个分片都是一个独立的 Lucene 库,读写操作就可以分摊到多个分片上
高扩展
- 将分片分散部署在多台机器上,每台机器为一个节点(Node)
- 通过增加 Node 缓解机器 CPU 占用过高带来的性能问题
高可用
考虑防止单个 Node 挂掉导致该 Node 中的所有分片都无法对外提供服务:
- 为分片增加副本,分为主分片(Primary Shard)和副分片(Replica Shard)
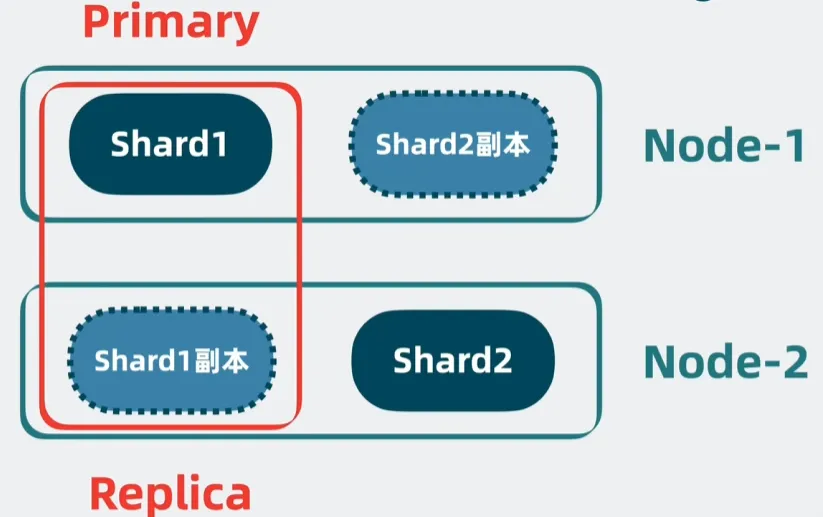
- 主分片会将数据同步给副分片,副分片能提供读操作,还能在主分片挂了的时候成为新的主分片