跳表是什么
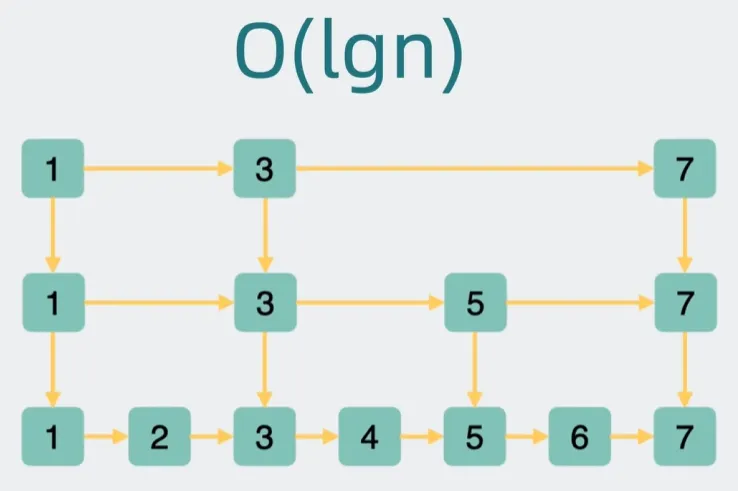
B+树和跳表的区别
- B+树的插入:
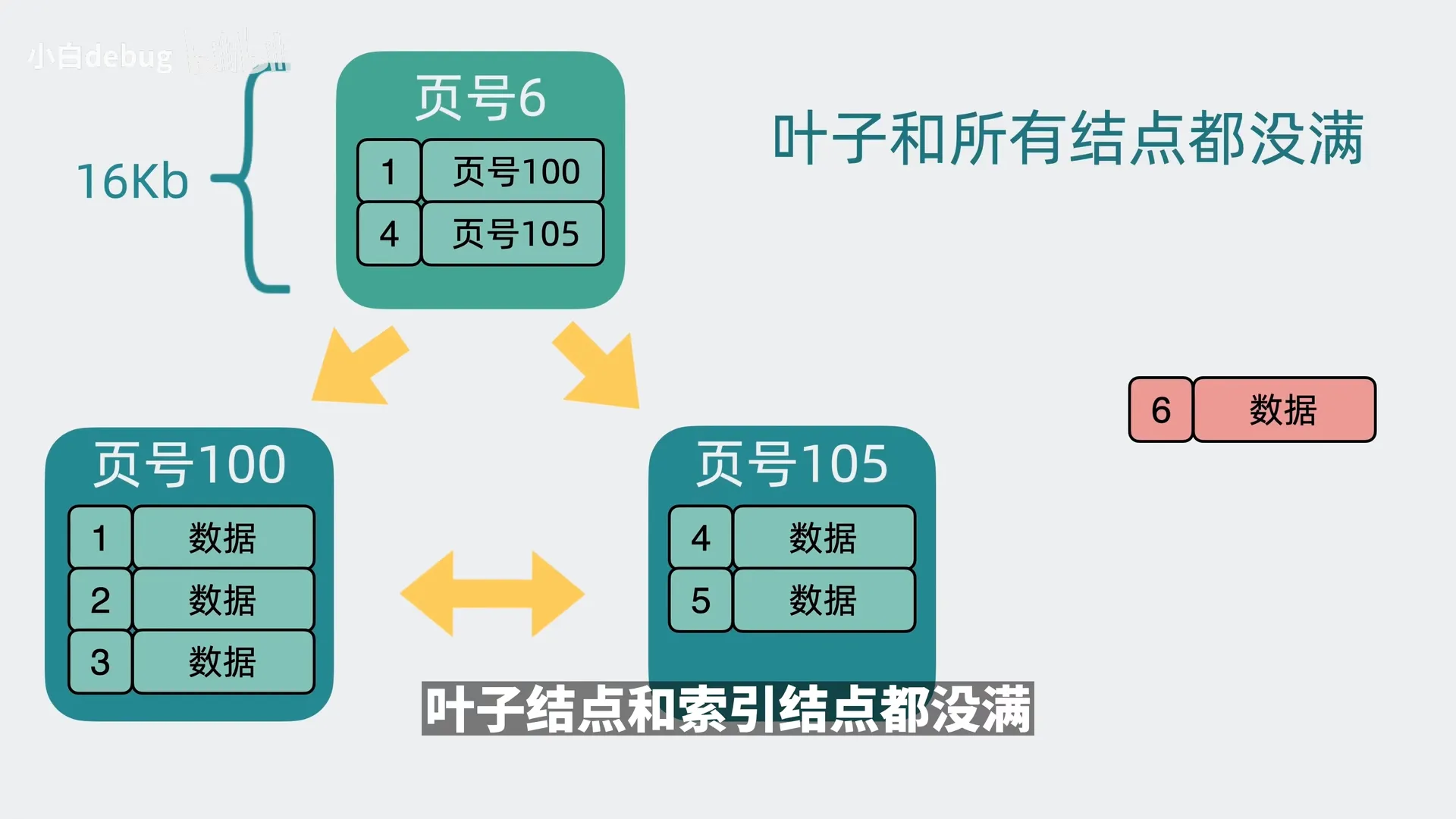
如果目标叶子节点没满,则直接插入;
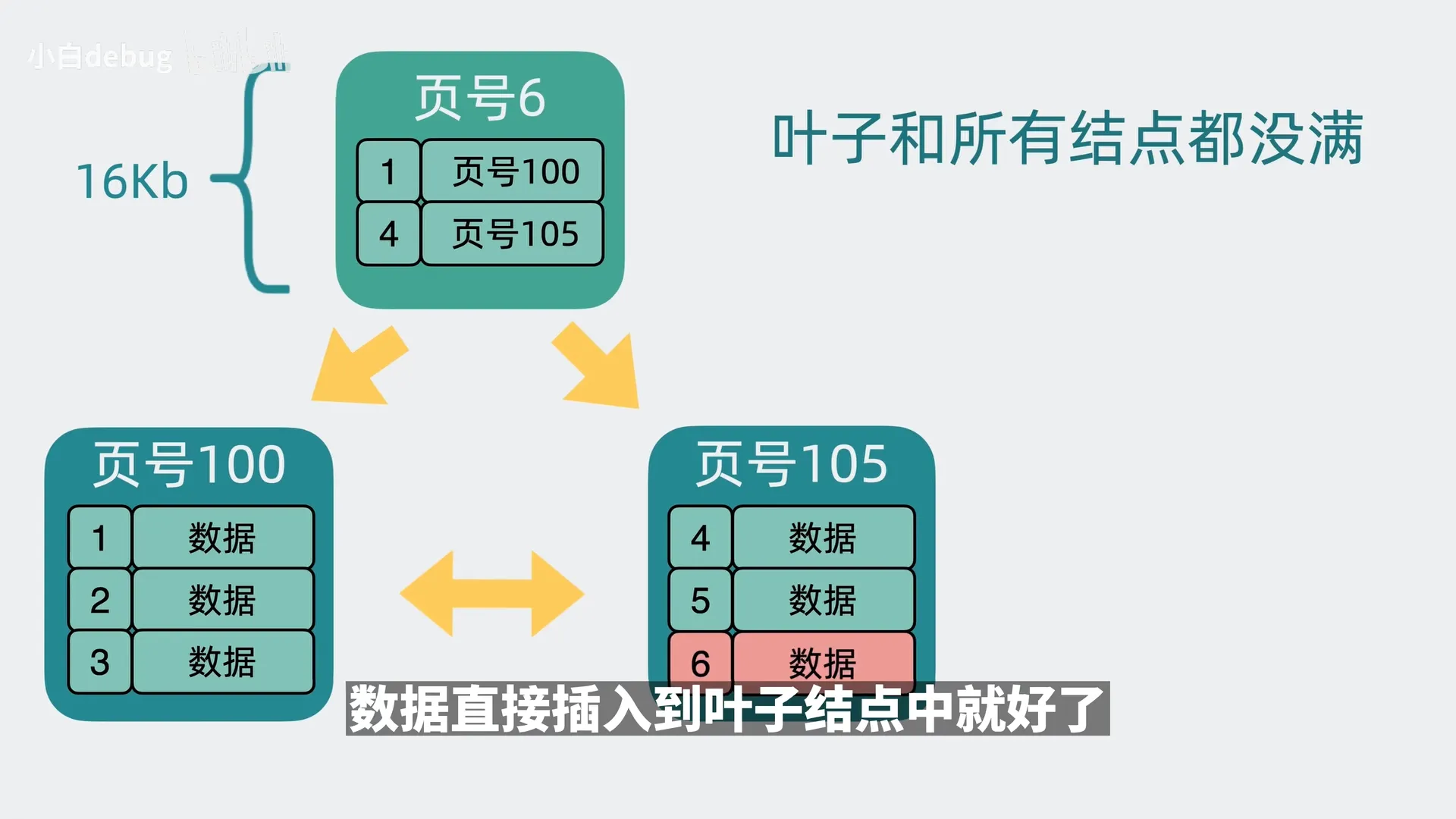 如果叶子节点满了,但索引节点没满,就需要叶子节点分裂并新增索引信息;
如果叶子节点满了,但索引节点没满,就需要叶子节点分裂并新增索引信息;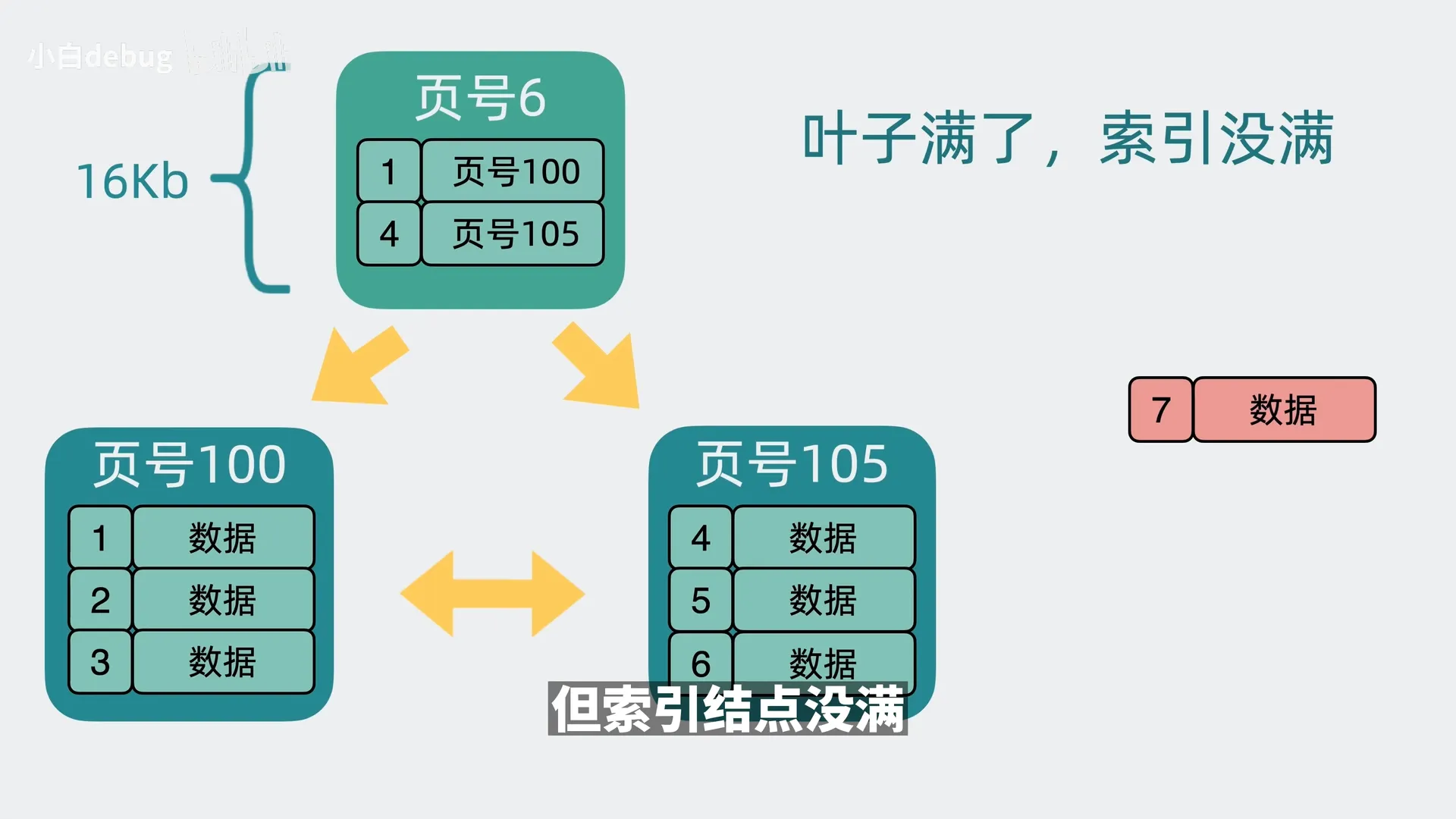
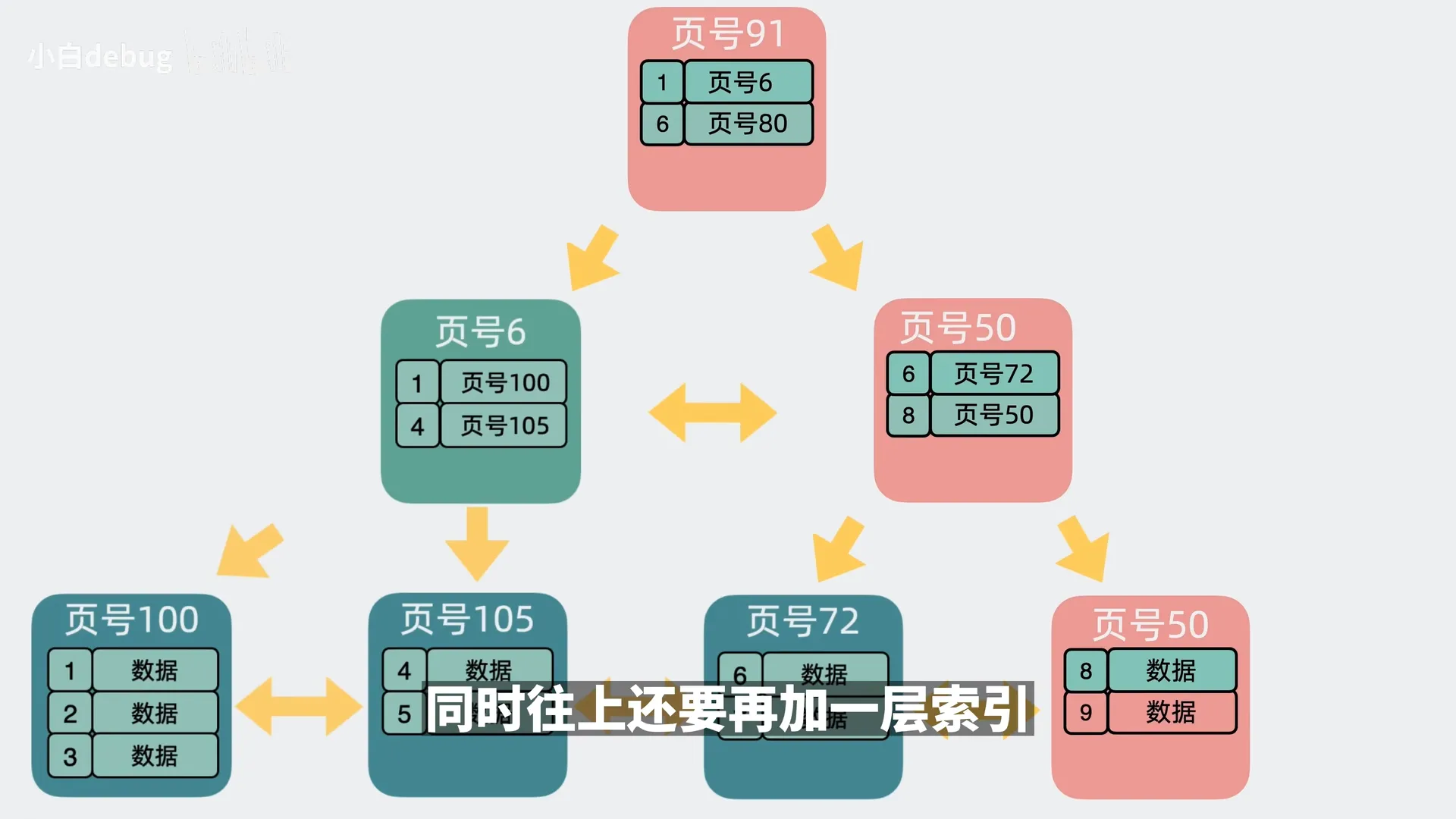
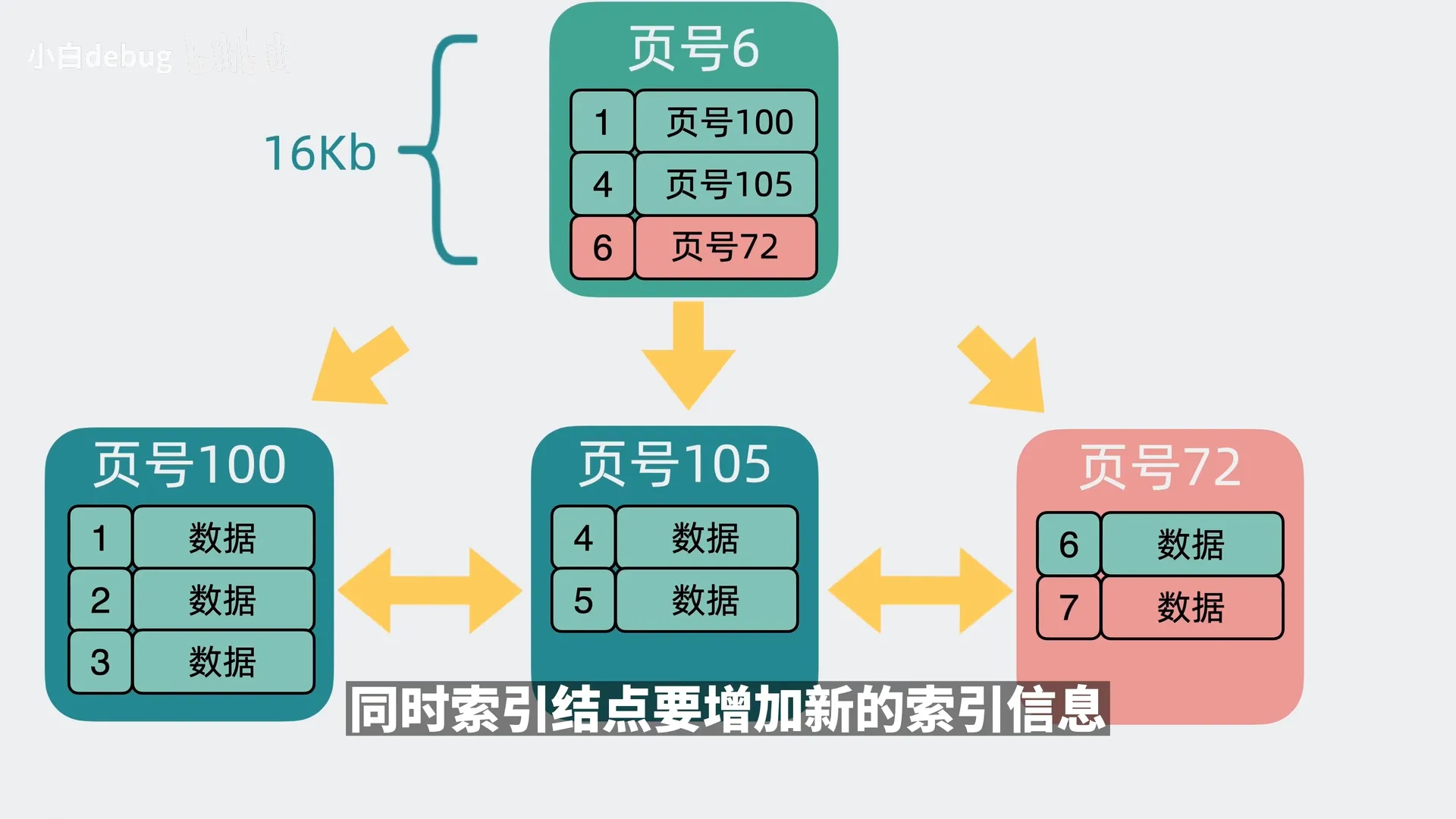 如果叶子节点和索引节点都满了,则叶子和索引节点都需要分裂并加一层索引;
如果叶子节点和索引节点都满了,则叶子和索引节点都需要分裂并加一层索引;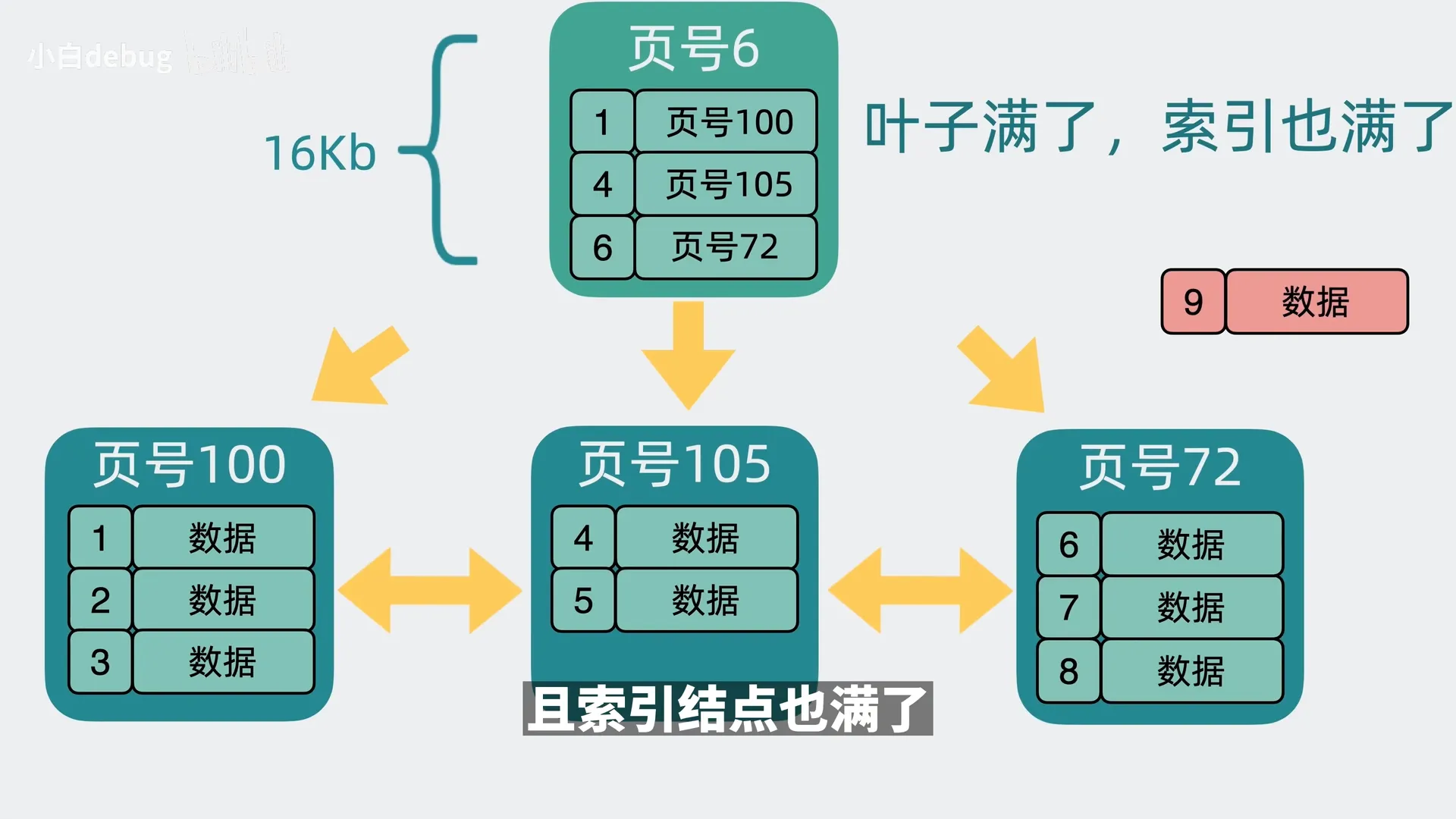
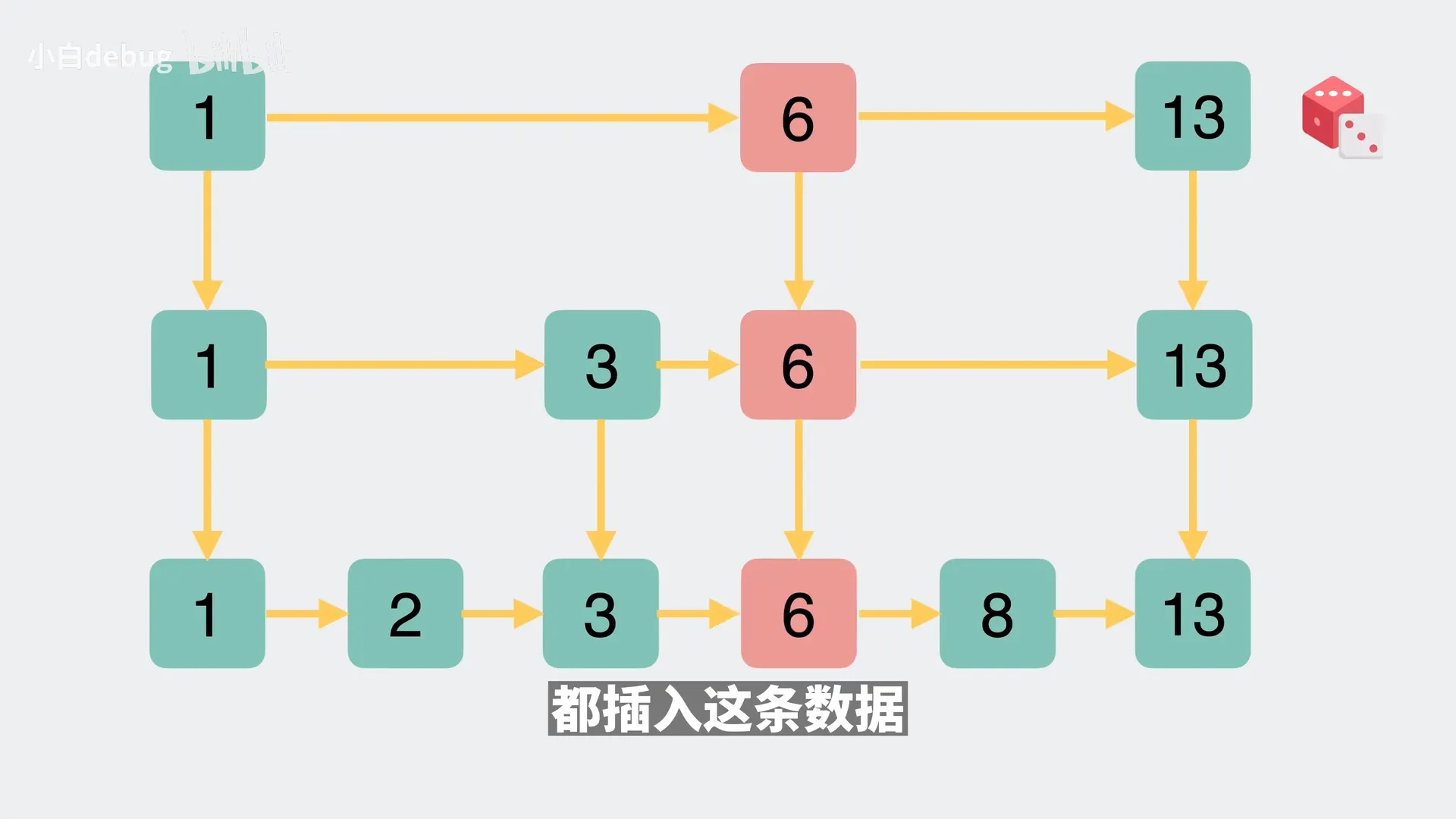
- 跳表的插入
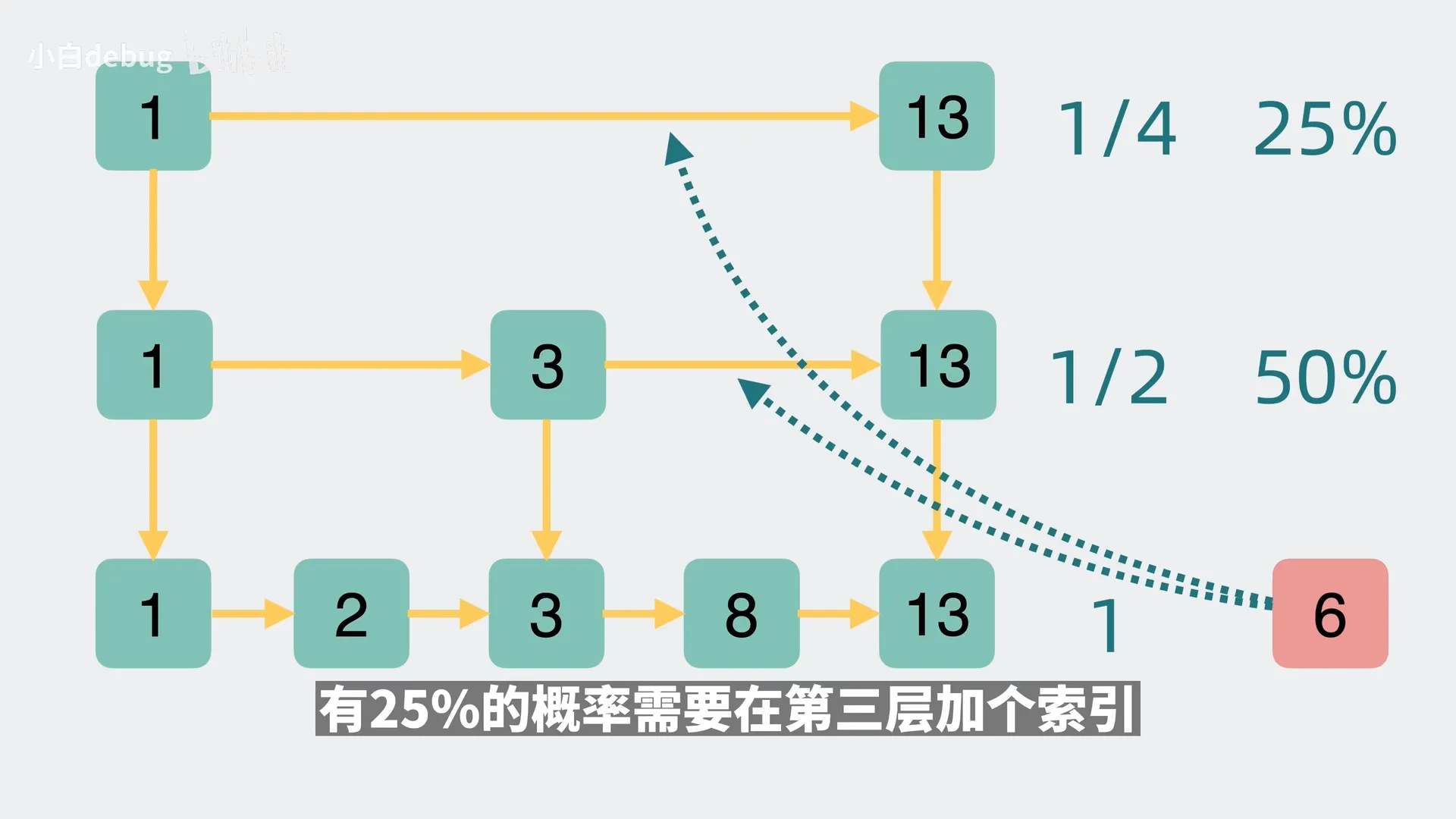
为了达到二分的效果,每一层的节点数需要是下一层的二分之一,新数据插入时,是否会在某一层加索引是随机的;
如图,新数据会有 50% 的概率在第二层加索引,有 25%的概率在第三层加索引
InnoDB 为什么选择 B+树?
- 对于查询数据:B+树的查询性能更好
- B+树每个节点的大小为 16KB,所以每个节点的分叉数可以非常多(1000+),3 层左右就可以存储 2000 万的数据,磁盘 I/O 以每个节点为单位,所以查询时只需要最多 3 次磁盘 I/O
- 而跳表如果要存储 2000 万数据,大约需要 24 层(因为要达到二分的效果,2 的 24 次方),查询时需要 24 次磁盘 I/O
- 对于插入数据:跳表的写入性能更好
- B+树的插入为了维持平衡,需要分裂、重构节点
- 跳表则是独立插入,根据随机函数决定层数 B+树在写入时只需修改 1~2 个页,同时InnoDB 在 B+树上的写入进行了很多优化,比如 WAL 批量提交,写入性能相较于跳表差距不大,综合考量下 B+树更优。
Redis 的 Zset 为什么选择跳表?
Redis 是内存数据库,所以没有磁盘 I/O 瓶颈,而且实现更简单同时性能不输平衡树。